Вы, вероятно, слышали вирусное утверждение, что каждый запрос к ChatGPT «выпивает» полбутылки воды. Если вы эксплуатируете или планируете инфраструктуру для рабочих нагрузок ИИ, реальный вопрос не в том, оправдана ли паника, а в том, сколько воды фактически потребляют ваши дата-центры ИИ, откуда берётся это число и что вы можете с этим сделать.
Согласно отчету Университета ООН, опубликованному в июне 2026 года, к 2030 году центры обработки данных искусственного интеллекта, обеспечивающие глобальные вычислительные нагрузки в этой области, будут потреблять ежегодно объем воды, эквивалентный базовым потребностям в воде 1,3 миллиарда человек. Это не показатель, рассчитанный на один запрос. Это совокупная картина, которая требует более тщательного анализа того, куда уходит эта вода.
Почему центрам обработки данных с ИИ требуется столько воды
Центры обработки данных искусственного интеллекта потребляют воду по двум причинам: для охлаждения серверов и для выработки электроэнергии, необходимой для их работы. Каждый кластер графических процессоров, на котором работают крупные языковые модели, выделяет огромное количество тепла. Большинство центров обработки данных используют системы испарительного охлаждения, в которых вода распыляется в потоки горячего воздуха — она испаряется в атмосферу и никогда не возвращается в местный водосборный бассейн.
Второй, зачастую более значительный источник находится за пределами территории. Термоэлектростанции, снабжающие электроэнергией центры обработки данных ИИ, используют воду для выработки пара и охлаждения. Согласно широко цитируемому исследованию Университета Калифорнии в Риверсайде 2023 года “Making AI Less Thirsty” («Как сделать ИИ менее «жаждущим»), вода, потребляемая на электростанциях, может составлять до 75% от общего водного следа, связанного с одним запросом ИИ. Если сложить объемы воды, используемой непосредственно для охлаждения, и косвенно — для производства электроэнергии, становится яснее полная картина водопотребления центров обработки данных ИИ — и она оказывается больше, чем показывают большинство оценок, учитывающих только потребление на территории объекта.
Помимо систем охлаждения и электроснабжения, производство микросхем добавляет ещё один этап в цепочке поставок. По оценкам ОЭСР, для производства одной микросхемы класса ИИ требуется примерно 2 200 галлонов сверхчистой воды. Хотя это и является разовыми затратами на каждую микросхему, огромное количество графических процессоров, установленных в настоящее время в центрах обработки данных ИИ, делает этот фактор нетривиальной составляющей в расчёте затрат на весь жизненный цикл.
Разбивка затрат на воду по каждому запросу
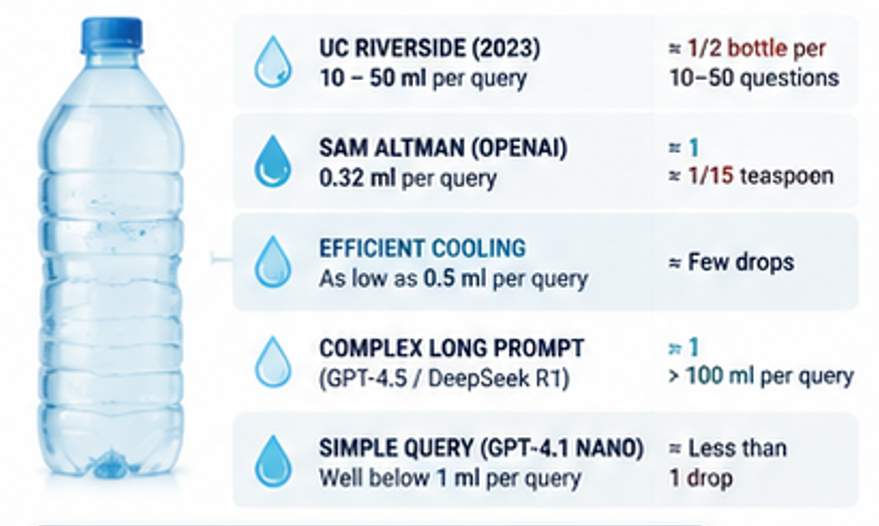
Показатели потребления воды на один запрос действительно невелики — но при этом крайне нестабильны в зависимости от того, кого спросить. Исследователи из Калифорнийского университета в Риверсайде подсчитали, что короткий разговор в ChatGPT, состоящий из 10–50 вопросов, потребляет примерно 500 миллилитров воды — это примерно одна стандартная бутылка воды — если учитывать как воду, используемую для охлаждения центров обработки данных, так и воду, потребляемую региональными электростанциями. Это составляет примерно от 10 до 50 миллилитров на один запрос.
Генеральный директор OpenAI Сэм Альтман позже привёл гораздо более низкую цифру: примерно 0,32 миллилитра на один запрос, или около одной пятнадцатой чайной ложки. С тех пор независимые аналитики утверждают, что многие широко распространенные оценки завышают реальные цифры в 50–250 раз, а расход воды непосредственно на месте для одного запроса может составлять всего 0,5 миллилитра при эффективных условиях охлаждения. В анализе China Economic Net за 2026 год, опирающемся на последние данные исследований, было подсчитано, что сложный запрос с длинным промтом к таким моделям, как GPT-4.5 или DeepSeek R1, может потреблять более 100 миллилитров воды, в то время как более простые запросы к меньшим моделям, таким как GPT-4.1 Nano, не превышают 1 миллилитра.
Вывод для вас прост: количество запросов в расчете на один запрос гораздо в большей степени зависит от размера модели, сложности запроса и местоположения дата-центра, чем от того, какую марку ИИ вы используете. Проблема заключается не в одном вашем сообщении, а в совокупности миллиардов сообщений.
Использование воды в центрах обработки данных с искусственным интеллектом в промышленных масштабах
На уровне отдельных объектов масштабы измеряются уже не чайными ложками, а миллионами галлонов. В июне 2026 года Брукингский институт сообщил, что типичный центр обработки данных для искусственного интеллекта потребляет примерно 300 000 галлонов воды в день, тогда как гипермасштабные объекты могут потреблять до 5 миллионов галлонов в день — это эквивалентно объему воды, потребляемому городом с населением от 10 000 до 50 000 человек.
Ежегодные отчеты компаний рисуют поразительную картину. Amazon сообщила, что в 2025 году её центры обработки данных AWS, использующие искусственный интеллект, потребляли по всему миру примерно 2,5 миллиарда галлонов воды. Google сообщила о потреблении более 6,1 миллиарда галлонов в 2024 году, Microsoft — примерно 2,75 миллиарда галлонов, а Meta — около 1,4 миллиарда галлонов. В совокупности эти четыре компании использовали более 12,7 миллиарда галлонов за один год — причем тенденция к росту потребления явно усиливается. Потребление воды компанией Microsoft подскочило на 34%, а Google — на 20% в том году, когда генеративный ИИ стал массовым явлением.
По прогнозам Института мировых ресурсов, к 2030 году инфраструктура центров обработки данных, связанных с искусственным интеллектом, может потреблять от 1,1 до 1,7 триллиона галлонов пресной воды в год. Для сравнения: общий объем потребления пресной воды во всех секторах экономики США составляет примерно 117 триллионов галлонов в год. Центры обработки данных для ИИ не опустошат океаны, но их сосредоточенный спрос в определенных регионах вызывает серьезную озабоченность.
Обучение и вывод: куда течет вода
Можно было бы предположить, что обучение — это этап, требующий наибольшего количества воды. По оценкам, на обучение GPT-3 было затрачено 700 000 литров пресной воды, а в отчете Университета ООН прогнозируется, что для обучения GPT-5 потребуется примерно 1 миллиард литров воды и 100 гигаватт-часов электроэнергии. Именно эти разовые затраты попадают в заголовки новостей.
Однако на инференцию — непрерывный процесс обработки запросов пользователей — приходится от 80% до 90% от общего объема потребления энергии и воды ИИ за весь срок службы модели. Согласно отчету Университета ООН, ChatGPT в настоящее время обрабатывает примерно 2,5 миллиарда пользовательских запросов ежедневно, что приводит к примерной годовой потребности в электроэнергии в размере 383 гигаватт-часов. Соответствующий водный след равен минимальным потребностям в воде примерно 500 000 человек в странах Африки к югу от Сахары.
Если вы внедряете вычисления на базе ИИ в широких масштабах, именно этот показатель имеет наибольшее значение для вашего оперативного планирования. Один-единственный цикл обучения становится новостью. А непрерывные вычисления — это расходы и рост показаний счетчика воды.
Какие центры обработки данных для искусственного интеллекта потребляют больше всего воды
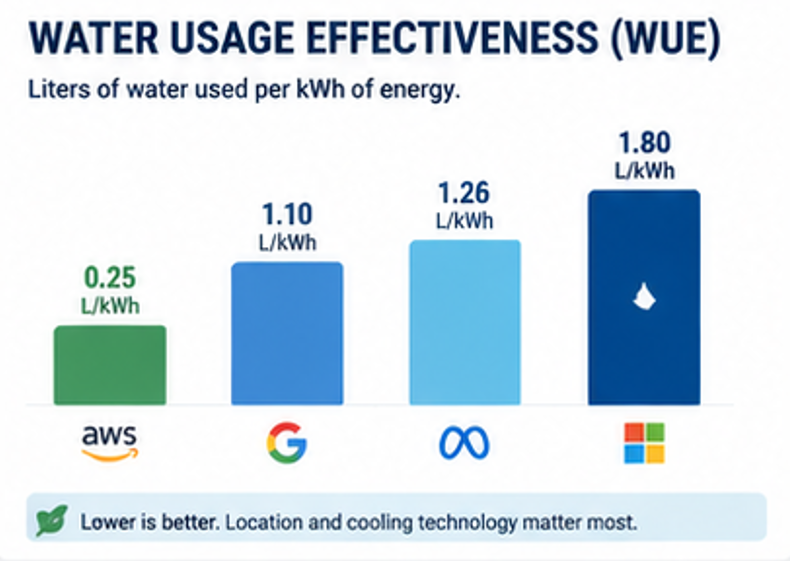
Ни одна компания, занимающаяся искусственным интеллектом, не публикует данные о потреблении воды на один запрос, поэтому для прямого сравнения приходится использовать оценочные данные. Однако можно измерить показатели эффективности использования воды. AWS сообщает о показателе примерно 0,25 литра воды на киловатт-час, что является самым низким показателем среди крупных облачных провайдеров. Средний глобальный показатель Google составляет около 1,1 литра на киловатт-час, у Meta — 1,26, а у Microsoft — примерно 1,8, согласно отчётам за 2022 год. С тех пор Microsoft объявила о цели достичь нулевого потребления воды к 2030 году.
Эти различия имеют значение, но географический фактор играет ещё более важную роль. Центры обработки данных в Аризоне, использующие испарительное охлаждение при температуре 40 °C, потребляют значительно больше воды, чем аналогичные объекты в Финляндии, где применяется естественное воздушное охлаждение. Согласно отчету Промышленной комиссии за 2025 год, более 40% запланированных центров обработки данных для искусственного интеллекта по всему миру расположены в регионах, классифицируемых как имеющие высокий или чрезвычайно высокий уровень дефицита водных ресурсов.
Когда местоположение вашего дата-центра имеет значение
Местоположение — это не просто одна из переменных WUE: от него зависит, станет ли ваш центр обработки данных с ИИ источником напряженности в местном сообществе. Центр обработки данных компании Meta в округе Ньютон, штат Джорджия, в настоящее время потребляет примерно 10% от общего объема водоснабжения округа. В округе Лаудон, штат Вирджиния — самом плотно застроенном центре размещения центров обработки данных в мире — центры обработки данных уже потребляют примерно 8% муниципальной воды, а по прогнозам к 2050 году этот показатель достигнет 29%.
Техас демонстрирует самые впечатляющие масштабы: по прогнозам, в 2024 году центры обработки данных в этом штате будут потреблять от 25 до 49 миллиардов галлонов воды, а аналитики прогнозируют, что к 2030 году этот показатель может взлететь до 399 миллиардов галлонов. В регионах, подверженных засухам, такая концентрация спроса в одной отрасли создает политический риск, который нельзя игнорировать. В Ирландии в 2023 году на долю центров обработки данных пришлось 21% всей учтенной электроэнергии, что превысило совокупное потребление всех городских домохозяйств, а потребление воды росло параллельно с этим.
Если вы оцениваете варианты колокации или облачные регионы для рабочих нагрузок, связанных с инференцией ИИ, индекс локального дефицита водных ресурсов должен занимать в вашей матрице принятия решений место наряду с показателями задержки и стоимости.
Как снизить водный след центров обработки данных, использующих ИИ
У вас есть несколько практических рычагов воздействия. Первый — это технологии охлаждения. Системы жидкостного охлаждения с замкнутым контуром и иммерсионного охлаждения рециркулируют воду вместо того, чтобы испарять её, что позволяет резко сократить потребление воды на объекте. Благодаря применению этих подходов новейшие центры обработки данных Google на базе TPU v5, предназначенные для искусственного интеллекта, потребляют значительно меньше воды на единицу вычислительной мощности, чем предыдущие поколения.
Второй аспект — планирование рабочих нагрузок. Исследования Университета Калифорнии в Риверсайде показали, что выполнение водоемких задач искусственного интеллекта в более прохладные ночные часы или в прохладные сезоны позволяет значительно сократить потери воды в результате испарения. Если ваш уровень оркестрации поддерживает планирование с учетом времени и местоположения, вы сможете сократить потребление воды без замены оборудования.
Третьим фактором является прозрачность и мониторинг. На большинстве объектов отсутствует детализированный учет потребления воды, а это означает, что невозможно оптимизировать то, что нельзя измерить. Внедрение инструментов мониторинга потребления воды в режиме реального времени позволяет получить данные по каждому серверному шкафу и каждой рабочей нагрузке, что превращает расплывчатую цель в области устойчивого развития в отслеживаемый операционный показатель.
Помимо технологий, программы по восполнению водных ресурсов становятся обязательным условием. Компания Amazon взяла на себя обязательство реализовать 50 проектов по восстановлению водных ресурсов, которые, по прогнозам, позволят ежегодно возвращать 5,8 миллиарда галлонов воды в местные водосборные бассейны. Google запустила 165 проектов по рациональному использованию водных ресурсов, нацеленных на пополнение запасов на 19 миллиардов галлонов в год к 2030 году. Это не решения проблемы потребления — это компенсационные меры — но они указывают на то, в каком направлении развиваются ожидания регулирующих органов и общественности.
Суть в том, что объем потребления воды центрами обработки данных с ИИ одновременно меньше и больше, чем об этом пишут в заголовках. Ваши отдельные запросы требуют объема воды, составляющего доли чайной ложки. Совсем другое дело — ваша инфраструктура в целом, обрабатывающая миллиарды запросов в регионах с дефицитом воды. Операторы, которые сегодня измеряют, раскрывают информацию и активно управляют потреблением воды, — именно они смогут избежать споров по поводу разрешений, противодействия со стороны местного населения и сбоев в работе, которые уже наблюдаются от Джорджии до Ирландии. Центры обработки данных для ИИ будут продолжать расти. Будут ли они расти ответственно — это выбор, который вы делаете каждый раз, выбирая регион, архитектуру охлаждения и набор инструментов мониторинга.

















{kind=link}